Paper Summary 3
Introduction
This is the third paper summary focusing on text summarizations, which I think is a good topic to get to know about natural language generation (NLG) and a challenging field since summarizing the documents has fewer identifications (for example chat-bot can use the time-series information …, t-1, t, t+1, …) to rely on.
Pre-trained models
- Paper:
MASS: Masked Sequence to Sequence Pre-training for Language Generation [paper]
- Background and motivation:
Other large models like BERT only pre-train the encoder or decoder, MASS is proposed to pre-train the encoder-decoder architecture jointly. Thus a better representation extractor and language model will be obtained.
-
Solution:
The idea is quite simple, the model adopts a seq-to-seq model and masks some tokens (e.g.: $x_3, x_4, x_5$) in the encoder and uses those unmasked tokens replaced with a special token [MASK] (e.g. $x_1, x_2,\,_,\,_,\,_,\,x_6, x_7\longrightarrow [MASK],\,[MASK],\,_,\,_,\,_,\,[MASK],\,[MASK]$) to reconstruct the masked tokens. The whole model is based on a Transformer architecture and pre-trained on monolingual data, later fine-tuned on three tasks: NMT, text summarization, response generation. The pre-training data is from WMT News Crawl datasets.
Highlights The shining point of this is the idea of jointly training encoder and decoder to extract high-quality representation and gain a competitive language model. To be more specific, it inherits a lot of training ideas from BERT (such as masking words) and I think the value of this work is that it pre-trains the decoder together, making not only discriminative but also generative tasks possible to have a powerful pre-trained reference.
- Architecture:
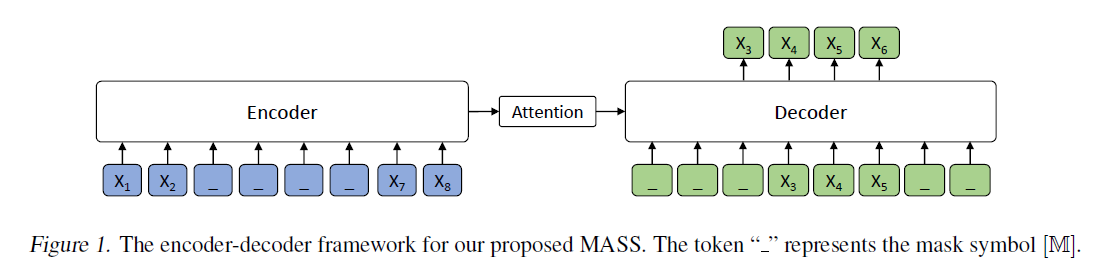
- Paper:
Unified Language Model Pre-training for Natural Language Understanding and Generation [paper]
- Background and motivation:
This model uses three different language modeling tasks (namely: unidirectional, bidirectional, sequence-to-sequence modeling) to improve the ability of a Transformer-based architecture.
-
Solution:
The unidirectional language modeling lets the model attend to words from one direction (left to right / right to left) ;
The bidirectional language modeling lets the model attend to words from both directions (like BERT) ;
The sequence-to-sequence modeling lets the model attend to words to be predicted (e.g.: $y_2$) using its context (e.g.: $x_1, x_2, x_3\,and\,y_1$)
And when pre-training, the above three objectives (for bidirectional Next Sentence Prediction (NSP) is used as well) are used averagely (1/3 for each) in every epoch. For fine-tuning on different tasks, [SOS] of the sentences are used or the concatenation of sentences is fed into the UniLM. And during testing, UniLM is used in a seq-to-seq architecture to decode for NLG tasks. The pre-training data is from English Wikipedia and BookCorpus.
Highlights The highlight of this work I think is the proposal of sequence-to-sequence modeling and training three language modeling objectives together. The usage of sequence-to-sequence modeling makes it more diverse to explore the context of sentences and thus possible to fine-tune for the NLG tasks.
- Architecture:
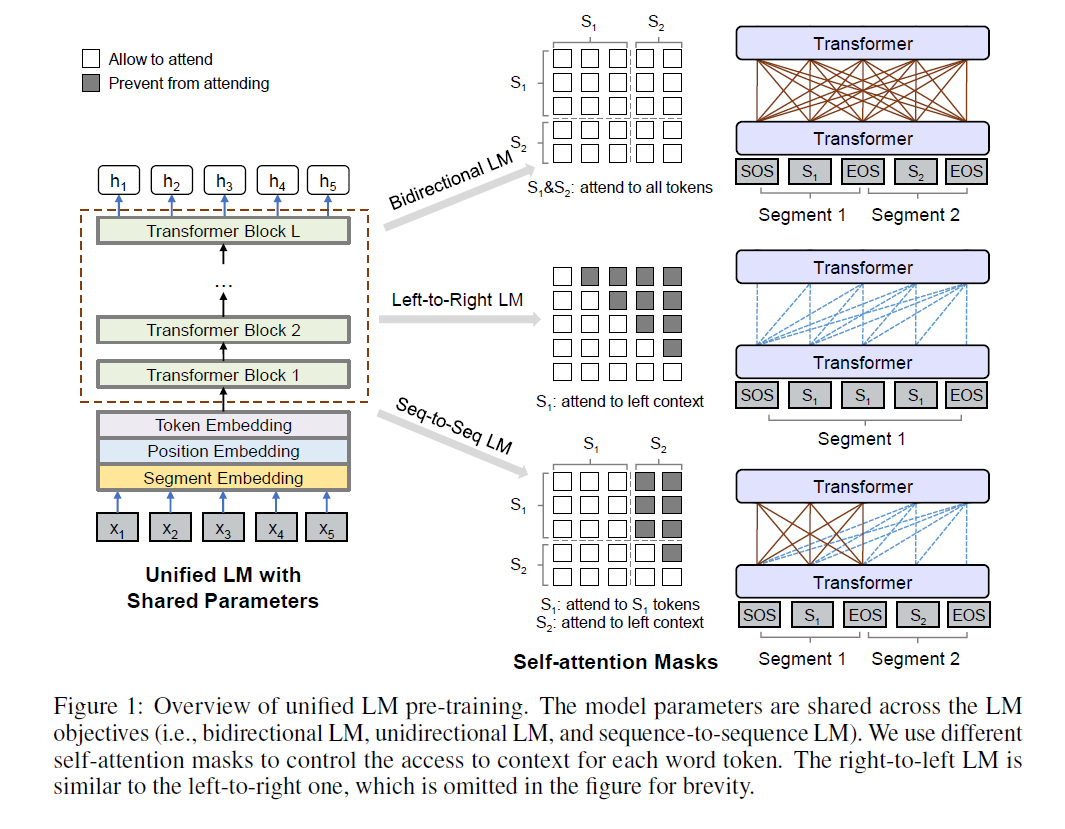
- Paper:
BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension [paper]
- Background and motivation:
BART can be viewed as a pre-trained large auto-encoder model. It is trained by first corrupting texts with a denoising function and then reconstructing the original text with the model. It uses the BERT encoder and the decoder from GPT. And since it naturally has a decoder, it is easy to be adapted to NLG tasks.
-
Solution:
In detail, BART’s decoder block performs an additional cross-attention operation with the outputs from the encoder, and compared with BERT, BART doesn’t add the feed-forward network before word prediction. The pre-training data is a combination of books and Wikipedia data.
It proposes five different pre-training objectives to train BART, namely: Token Masking, Token Deletion, Text Infilling, Sentence Permutation, Document Rotation.

For Token Masking, it simply follows BERT ;
For Token Deletion, it randomly deletes tokens and the model will decide which positions of the inputs are missing ;
For Text Infilling, it randomly selects a span with length from a Poisson distribution ($\lambda=3$) and replaces them with a single [MASK] token. Interestingly, when the length is 0, it becomes an insertion of the [MASK] token. (see above, the second sentence “DE.” becomes “D_E.”)
For Sentence Permutation, it shuffles the sentences (indicated by a full stop) in a document.
For Document Rotation, firstly a token is chosen randomly and then used as a pivot to rotate the document.
When fine-tuning, for classification tasks, the same sentence sequence is fed into the encoder and decoder, and the final hidden state is used for prediction; for generation tasks, the BART architecture naturally has a decoder; for NMT especially, BART uses a randomly initialized encoder (same architecture as the pre-trained encoder in BART) to serve as the encoder for another language, thus BART can preserve its pre-trained knowledge on the monolingual data.
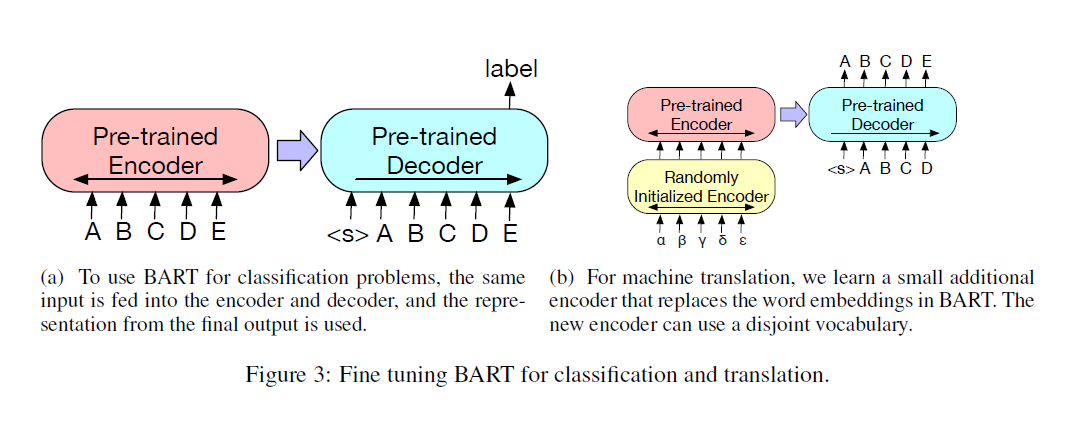
For comparison, the authors also propose several pre-training objectives: a. Language Model (a left-to-right transformer) ; b. Permuted Language Model (XLNet based, sample 1/6 tokens and generate them auto-regressively in a random order) ; c. Masked Language Model (BERT based) ; d. Multitask Language Model (UniLM based, 1/6 left-to-right, 1/6 right-to-left, 1/3 unmasked, 1/3 with the first 50% unmasked and the rest 50% of a left-to-right mask) ; e. Masked Seq-to-Seq (MASS based, a span containing 50% words is masked then a seq-to-seq model is trained to predict them) And for b, c, d, two-stream attention is used (see paper [here]).
Highlights I really like this work since it uses the simple idea of denoising auto-encoder (DAE) and shows a good example of combining two powerful architectures (BERT encoder + GPT decoder). The various forms of denoising functions are also very creative (especially the Text Infilling function, which can be seen as the combination of Token Masking and the reverse version of Token Deletion).
- Architecture:
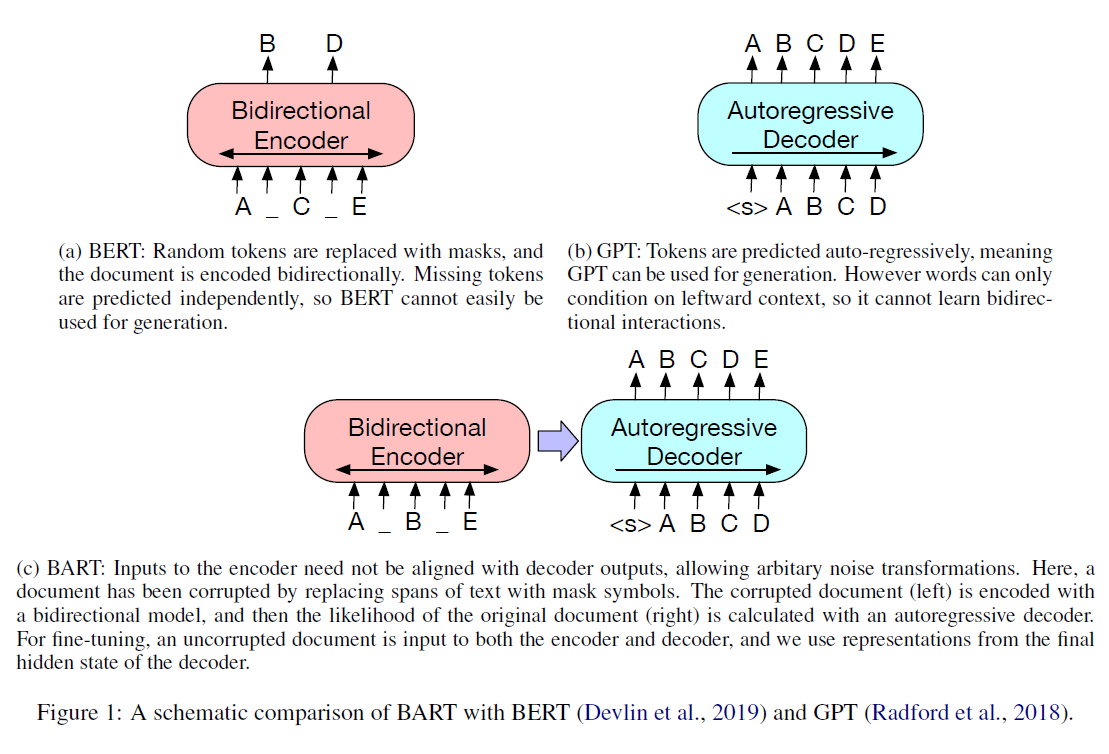
- paper
PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization [paper]
- Background and motivation:
PEGASUS is specifically designed for abstractive summarization, where instead of masking some words, it masks a whole sentence and tries to generate them during pre-training, which gives the model the ability to understand the document at sentence-level, thus achieving a better performance.
-
Solution:
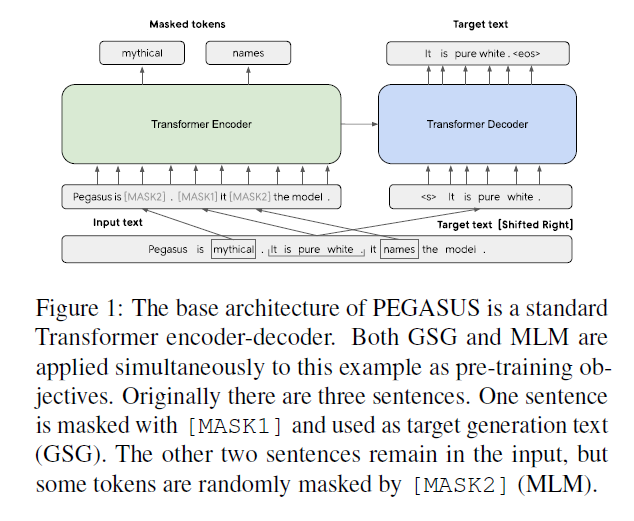
The model is Transformer encoder-decoder based, and two pre-training objectives are used: namely Gap Sentence Generation (GSG) and Masked Language Model (like BERT). In the proposed GSG, it selects some “gap” sentences and uses one single token [MASK1] to mask the whole sentence (for MLM it uses [MASK2] to mask some words). And there’re three selecting strategies for GSG: 1. randomly select $m$ sentences (Random); 2. select the first $m$ sentences (Lead); 3. select the top-$m$ importance sentences by calculating the ROUGE-F1 score between the selected sentences and the rest in the document (Principal), where sentences are either scored independently against each other (Ind) or sequentially by greedily maximizing the ROUGE-F1 of the selected top-$m$ sentences and the rest (Seq). When calculating ROUGE-F1, the original setting is by double-counting identical n-grams (Orig), and can be calculated by consider n-grams as a set (Uniq).
Thus, for Principal, there are four selecting criteria ({Ind/Seq}, {Orig/Uniq}).
The model is pre-trained on C4 and HugeNews and the two pre-training objectives are jointly used as shown in Architecture.
Highlights The reason behind the success of PEGASUS is the simultaneous usage of sentence-level mask and word-level mask, which enables the model to understand the meaning of sentences (word-level mask, doing language modeling) and to comprehend the content of the sentence in the document (sentence-level mask, doing sentence-level comprehension). These two objectives make the model suitable for summarizing over documents while maintaining good “reading” ability.
Survey
- Paper:
A Survey on Dialogue Summarization: Recent Advances and New Frontiers [paper]
- Background and motivation:
Summarizing dialogues into a shorter and salient version is of great value and research interests, and there lacks a comprehensive survey; thus this work is proposed.
-
Main content:
The survey focuses on dialogue summarization models w.r.t. the domains that the models are working on. Namely, Meeting, Chat, Medical Dialogue, Customer Service, Email Threads, and Others.
For Meeting Summarization, the various interaction signals and the existence of multi-modal materials (such as video, image) can be considered besides the texts;
For Chat Summarization, the problem lies in the complex conversational interactions (for example, in a chatting room, multiple participants may talk about on one topic and then move to another). Thus, it is difficult to keep track of the content of the conversation, such difficulty leads to factual inconsistency;
For Email Threads Summarization, it is an asynchronous multi-party communication involving texts exchanging among multiple participants. The inherently available action items (such as “A send to B”) and the coarse-grained intents at email level can be paid more attention to;
For Customer Service Summarization, there is conversation between a agent and a customer; thus, understanding the roles of speaker, the change of topics are very important. Moreover, some insights and characteristics from relative tasks can be considered (for example, consider “slot” and “intent” in summarization inspired by slot filling and intent detection tasks) ;
For Medical Dialogue Summarization, it is important to be faithful to the dialogue since the summarization should capture precise information about facts, such as the name of a drug, the therapy, and the diagnoses. Thus, an extractive way combined with some slight abstractive manner is preferred. Note that Medical Dialogue Summarization still face the challenge of factual inconsistency;
For Other Types of Dialogue Summarization, summarization tasks focusing domains in podcasts, online discussion forums, legal debates and reader comment threads have been proposed. There is task tackling personalized chat summarization problem;
Highlights I think the most valuable part of this survey is the proposed possible frontiers: a. Faithfulness (related to factual inconsistent problem, and is as well potential in replacing ROUGE to serve as a new criterion) ; b. Multi-modal (may be very helpful for summarizations involving multimedia, such as Meeting Summarization) ; c. Multi-domain (can be divided into Macro and Micro, for Macro, it uses general domain summarization tasks, e.g. News to help a specific summarization task, e.g. Meeting. For Micro, it uses specific domain summarization tasks, e.g. Meeting to help another specific task, e.g. Email Threads. ) ;
Models based on pre-trained models and everything else
- Paper:
Text Summarization with Pretrained Encoders [paper]
- Background and motivation:
Leverage BERT to get a powerful text summarization model for both extractive and abstractive tasks.
-
Solution:
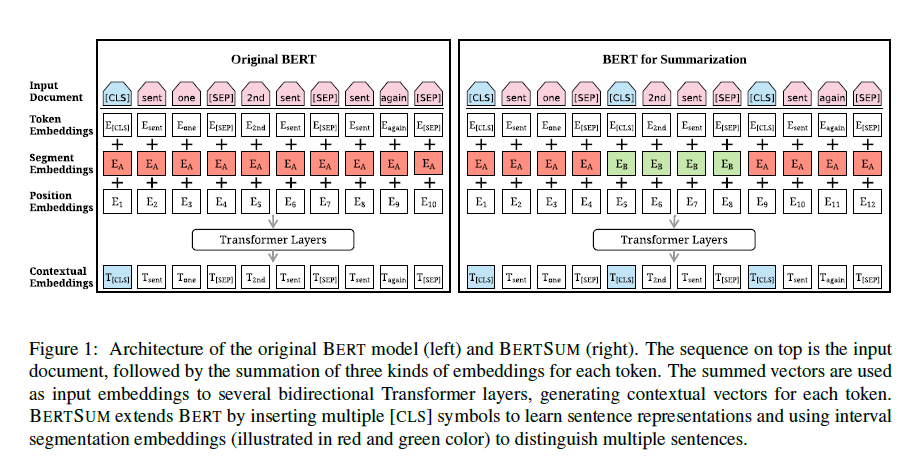
To leverage BERT for summarization tasks, a few modifications are done to the embeddings of the original BERT. First, the [CLS] token is added to every input sentence to collect the information of each sentence. Second, unlike BERT, this paper apply interval segment embeddings to distinguish each sentence, in detail, [$E_A$] for odd sentences and [$E_B$] for even sentences. (in BERT there are usually two sentences, thus [$E_A$] and [$E_B$] don’t appear alternatively).
With the above modified BERT encoder (BERTSUM), several Transformer layers are stacked above BERTSUM and then classified for extractive summarization task. For abstractive task, the BERTSUM encoder is used together with Transformer decoders in a seq-to-seq model. A two-stage fine-tuning approach is proposed by first fine-tune on the extractive task and then fine-tune it on the abstractive task.(According to the authors, “Previous work (Gehrmann et al., 2018 {see [paper]}; Li et al., 2018 {see [paper]}) suggests that using extractive objectives can boost the performance of abstractive summarization.”)
Highlights The idea is quite simple, only a few modifications have been done to leverage BERT for summarization tasks. However it goes without saying that this work is important, since it shows the potential of BERT in summarization tasks and provides a useful general framework for both extractive and abstractive tasks.
- Architecture:
- Paper:
RefSum: Refactoring Neural Summarization [paper]
- Background and motivation:
The aggregation of different SOTA summarization models can complement each other and achieve potential performance gain. However, the aggregation techniques (Meta stage) such as stacking, re-ranking are separated from the training of models (Base Stage), which leads to following limits:
a. Ad-hoc Methods: previous models are designed for a specific scenario.
b. Base-Meta Learning Gap: Summarization and combination of models use different architectures.
c. Train-Test Distribution Gap: Let $Hypo_{base}$, $Hypo^{‘}_{base}$ denote the training / test outputs from summarization models in Base Stage, and $Hypo_{meta}$, $Hypo^{‘}_{meta}$ (both are the outputs from Base Stage) denote that of the aggregation model in Meta Stage. The gap lies between the distributions of $Hypo_{meta}$, $Hypo^{‘}_{meta}$.
To address the above challenges, this work proposes a general framework that can both summarize and aggregate.
-
Solution:
The previous works can be denoted as follows:
\[\mathcal{C}=\{C_i\,|\,C_i=BASE^{i}\,(D,\,\tau,\,\mathcal{S},\,\theta^{base})\}\longrightarrow C^{*}=META\,(D,\,\mathcal{C},\,\theta^{meta})\] Where $\mathcal{C}$ is the set of candidate summaries. Each summary $C_i$ comes from summarization on document $D$ w.r.t. different parameterization choices on the system $BASE\,(·)$ and $\tau,\,\theta$ denote the training method and decoding strategy, respectively. The combination model $META\,(·)$ complements the candidates to produce the final summary $C^{*}$.
The proposed model is called Refactor, which unifies the Base Stage and Meta Stage:
\[C^{*}=REFACTOR\,(D,\,\mathcal{C},\,\theta^{refactor})\]where $REFACTOR\,(·,\,\theta^{refactor})$ is the Refactor model.
The model adapts a pre-train then fine-tune learning pattern, for pre-training, the model serves as a scoring function:
where $\textbf{D},\,\textbf{C}_i$ are representations encoded by BERT and $SCORE(·)$ is a similarity scoring function implemented by BERT and Transformer blocks. The candidate set $\mathcal{C}$ is constructed by enumerating possible combinations of sentences in document $D$ where unreasonable combinations are pruned to control the sentence quality in $\mathcal{D}$. And when fine-tuning, the previous pre-trained model takes outputs from some base systems to fit the distribution of specific types of data. As a unified framework, the objective is a ranking loss: $L=\sum_{i}\sum_{j>i}max(0,\,SCORE(\textbf{D},\,\textbf{C}_j)-SCORE(\textbf{D},\,\textbf{C}_i)+(j-i)*\lambda_c)$ where $ROUGE(C_i,\,\hat{C})>ROUGE(C_j,\,\hat{C})$ for $i<j$ and $\hat{C}$ is the reference summary. In application, the model can serve as either a model in Base Stage generating summaries or a combination model in Meta Stage complementing different candidates.
Highlights This architecture is quite simple and effective. The idea of unification is very inspiring, which can be am alternative perspective in the future work.
- Architecture:
No graphic illustration in the paper
- Paper:
Exploring Multitask Learning for Low-Resource Abstractive Summarization [paper]
- Background and motivation:
Many tasks combined together can help improve the performance of abstractive tasks (especially in a low resource scenario); thus it’s worth exploring what kind of tasks can benefit abstractive summarization.
-
Solution:
For a low-resource dataset (with only a few training data), this paper proposes four auxiliary tasks to perform multitask learning, namely, extractive summarization, concept detection, paraphrase detection, language modeling. These tasks will help to improve the performance of abstractive summarization. And two popular framework, BERT and T5 are used for experiment.
For BERT, in extractive summarization, a linear layer is added after the encoder’s outputs to classify which sentence is selected with input format of $[CLS]\,DW_1,\,…,DW_n\,[SEP]SW_1,\,…,SW_m$ where $DW_i$ is the $i$-th word of the document and $SW_j$ is the $j$-th word of the sentence to be classified. For concept detection, the model classify whether the word in a sequence is part of a concept extracted by a TF-IDF algorithm and the paraphrasing detection task asks the model to decide whether two input sentences $[CLS]\,Sent_1\,[SEP]\,Sent_2$ express the same idea with different phrasing. The language modeling task is directly from BERT. Note that when training, the paraphrasing detection task uses the MSRP dataset to train (which introduces new data) and the rest tasks all take the same dataset to do multitask learning (which in fact provides a multi-view towards the same data for the model). The overall training strategy for BERT is shown as follows.
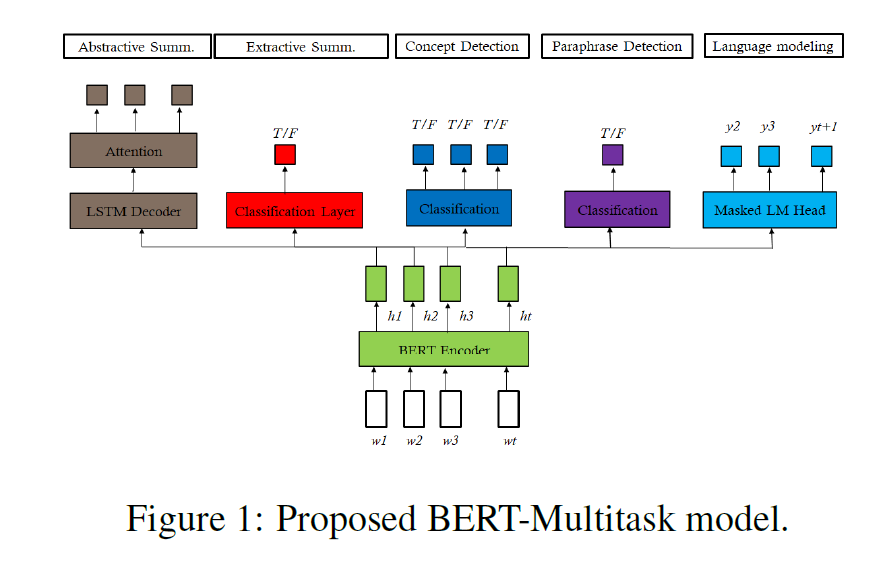
And the following figure is the training settings for T5.
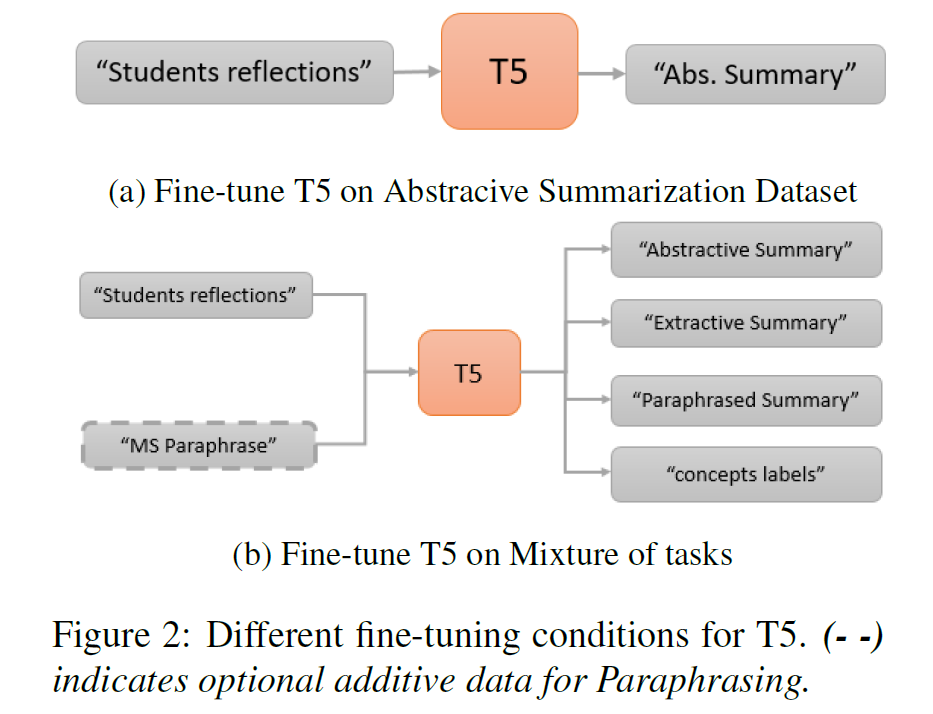
And when training, the multiple tasks are trained consecutively, in detail, after task 1 is trained, task 2 is to be trained and son on.
Highlights I really like the idea of proposing multitask learning for low-resource data, since the limitations on the amount of available data requires us to utilize the data as much as possible, leveraging multitask learning gives the model multiple views towards the same data, thus, exploring the data throughly. However, besides the brilliant idea of multitask learning on low-resource data, the patterns this paper found that paraphrasing detection can help improve the performance of abstractive summarization under low-resource settings are not that CONVINCING, since when doing paraphrasing detection,it is performed on the MSRP dataset, which introduces new data to the model besides the original ones.
- Architecture
see above
Enjoy Reading This Article?
Here are some more articles you might like to read next: