Paper Summary 2(special edition)
Introduction
This is the second paper summary focusing on the ‘best paper award’ winners of IJCAI (2015~2022), and if you want to see some other best papers of AI related major conferences, please refer to [here]. And as a special edition of the ‘paper summary’ series, here I only focus on the ‘abstract’ and ‘introduction’ part (which I may quote directly from the paper) instead of the architecture.
2020
- Paper
A Multi-Objective Approach to Mitigate Negative Side Effects [paper]
- Abstract
“Agents operating in unstructured environments often create negative side effects (NSE)$^1$ that may not {$\longleftarrow$ 1. explain current problems, which is ‘NSE’} be easy to identify at design time. We examine$^2$ how various forms of human feedback or autonomous exploration can be used to learn a penalty function associated with NSE during system deployment. {$\longleftarrow$ 2. what research we did towards the problem} We formulate the problem$^3$ of mitigating the impact of NSE as a multi-objective Markov decision process with lexicographic reward preferences and slack. The slack denotes$^3$ the maximum deviation from an optimal policy with respect to the agent’s primary objective allowed in order to mitigate {$\longleftarrow$ 3. the main work we’ve done in this paper} NSE as a secondary objective. Empirical evaluation of our approach$^4$ shows that the proposed framework can successfully mitigate NSE and that different feedback mechanisms introduce different biases, which influence the identification of NSE.” {$\longleftarrow$ 4. the results/improvement gains of our work}
-
Introduction
-
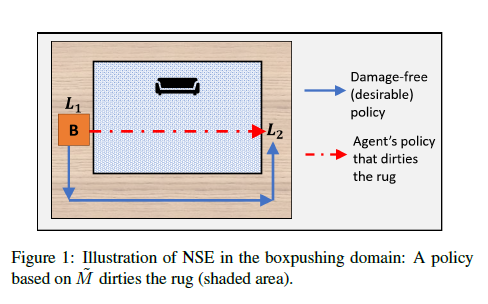
A detailed explanation of why ‘NSE’ will happen:
“but inevitably details in the environment that are unrelated to the agent’s primary objective are ignored” “As a result of the limited fidelity of $\tilde{M}$ , the agent’s actions may have unmodeled, undesirable negative side effects (NSE) in some states”
-
What we focus on:
“We focus on NSE that are undesirable but not prohibitive.”
-
The importance of our work (to eliminate ‘NSE’) and the efforts from previous work:
“Learning to detect and minimize NSE is critical for safe deployment of autonomous systems” “Existing works (outlined in Table 1) mitigate NSE by recomputing the reward function for the agent’s primary objective”
-
Our work (following quotes are with sequential-time order) and a summary on the contribution:
“We propose a multi-objective approach that exploits …”$^1$ “The agent’s primary objective is to achieve its assigned task, while the secondary objective is to minimize NSE.”$^2$ “We investigate the efficiency of different feedback approaches …”$^3$ “Our primary contributions are: (1) …”
in ‘1’—the main methods and why are using them are discussed
in ‘2’—how the proposed methods work
in ‘3’—how are the experiments and ideas behind them
-
- Paper
Synthesizing Aspect-Driven Recommendation Explanations from Reviews [paper]
- Abstract
“Explanations help to make sense of recommendations, increasing the likelihood of adoption. However, existing approaches to explainable recommendations tend to rely on rigid, standardized templates, customized only via fill-in-the-blank aspect {$\longleftarrow$ 1. point out the existing limits of the field} sentiments. For more flexible, literate, and varied explanations covering various aspects of interest, we synthesize an explanation by selecting snippets from reviews, while optimizing for representativeness and coherence. To fit target users’ aspect preferences, we contextualize the opinions based on a compatible explainable recommendation model. {$\longleftarrow$ 2. introduce the motivations and our solution} Experiments on datasets of several product categories showcase the efficacies of our method as compared to baselines based on templates, review summarization, selection, and text generation.” {$\longleftarrow$ 3. explain experiment results (on which how it showed the model is good)}
-
Introduction
This is a quite different introduction since it actually has had itself organized by using the bold, descriptive titles in ‘Introduction’
-
Introducing the task:
“Explainable recommendations are motivated by the need for …”
-
Explain the existing problems and previous attempts towards the problem
“Problem. An explanation is typically generated post hoc to the recommendation model.” “For instance, EFM [Zhang et al., 2014] has standardized templates for positive and negative opinions, each time substituting only the [aspect], e.g.,:”
-
Introducing our contributions: (which includes the brief introduction of the contents of each following subsection)
“Contributions. We make several contributions in this work.”
-
2019
- Paper
Boosting for Comparison-Based Learning [paper]
- Abstract
“We consider the problem of classification in a comparison-based setting: given a set of objects, we only have access to triplet comparisons of the form object $x_i$ is closer to object $x_j$ than to object {$\longleftarrow$ 1. specify the setting of the task/ introducing background} $x_k$. In this paper we introduce TripletBoost, a new method that can learn a classifier just from such triplet comparisons. The main idea is to aggregate the triplets information into weak classifiers, which can subsequently be boosted to a strong classifier. {$\longleftarrow$ 2. the motivation/idea of this work} Our method has two main advantages: (i) it is applicable to data from any metric space, and (ii) it can deal with large scale problems using only passively obtained and noisy triplets. We derive theoretical generalization guarantees and a lower bound on the number of necessary triplets, and we empirically show that our method is both competitive with state of the art approaches and resistant to noise.” {$\longleftarrow$ 3. the gains/improvements of our methods}
-
Introduction
-
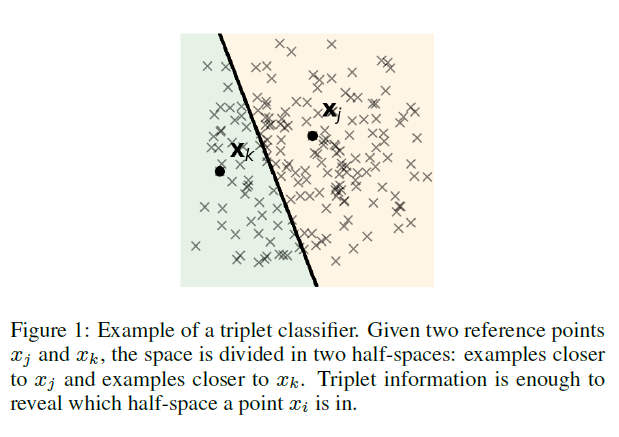
Introduce what is ‘comparison-based learning’:
“In the past few years the problem of comparison-based learning has attracted growing interest …”
-
Specifically explain the proposed setting/ assumption/ question in this work:
“We address the problem of classification with noisy triplets that have been obtained in a passive manner: the examples lie in an unknown metric space, …”
“Another interesting question in this context is that of the minimal number of triplets required to successfully learn a classifier. …”
-
Further introduction to our proposed method, and why they are efficient:
“In this paper we propose TripletBoost …”
“Our method is based on the idea that the triplets can be aggregated into simple triplet classifiers, …”
“From a theoretical point of view we prove that …”
“From an empirical point of view we demonstrate that”
-
and for ‘triplet classifiers’, there is a demonstration:
2018
- Paper
A Degeneracy Framework for Graph Similarity [paper]
- Abstract
“The problem of accurately measuring the similarity between graphs is at the core of many applications in a variety of disciplines. Most existing methods for graph similarity focus either on local or on global properties of graphs. However, even if graphs seem very similar from a local or a global perspective, they may exhibit different structure at {$\longleftarrow$ 1. point out the problems for measuring graph similarity} different scales. In this paper, we present a general framework for graph similarity which takes into account structure at multiple different scales. The proposed framework capitalizes on the well-known k-core decomposition of graphs in order to build a hierarchy of nested subgraphs. We apply the framework to derive variants of four graph kernels, namely graphlet kernel, shortest-path kernel, Weisfeiler-Lehman subtree kernel, and pyramid match graph kernel. The framework is not limited to graph kernels, but can be applied to any {$\longleftarrow$ 2. present the work and its main appealing properites} graph comparison algorithm. The proposed framework is evaluated on several benchmark datasets for graph classification. In most cases, the corebased kernels achieve significant improvements in terms of classification accuracy over the base kernels, while their time complexity remains very attractive.” {$\longleftarrow$ 3. summary of the gains of the proposed method based on experiment}
-
Introduction
-
Introducing graph and the importance of the kernel (background):
“Graphs are well-studied structures which are …”
“So far, kernel methods have emerged as one of the most effective tools for graph classification, and …”
-
A general introduction of the kernel and some lacks:
“Most graph kernels in the literature are instances of …”
“Most existing graph kernels can thus be divided into two classes. …”
“Therefore, existing graph kernels focus mainly on either local or global properties of graphs. In practice, it would be desirable to have a kernel that can take structure into account at multiple different scales”
-
Summary on our work:
“In this paper, we propose a framework for comparing structure in graphs at a range of different scales.”
“More specifically, the contributions of this paper are threefold:”
-
- Paper
Commonsense Knowledge Aware Conversation Generation with Graph Attention [paper]
- Abstract
“Commonsense knowledge is vital to many natural language processing tasks. In this paper, we present a novel open-domain conversation generation model to demonstrate how large-scale commonsense knowledge can facilitate language understanding {$\longleftarrow$ 1. explain what this work did in general} and generation. Given a user post, the model retrieves relevant knowledge graphs from a knowledge base and then encodes the graphs with a static graph attention mechanism, which augments the semantic information of the post and thus supports better understanding of the post. Then, during word generation, the model attentively reads the retrieved knowledge graphs and the knowledge triples within each graph to facilitate better generation through a dynamic graph attention mechanism. {$\longleftarrow$ 2. the more detailed working flow process of the proposed method} This is the first attempt that uses large-scale commonsense knowledge in conversation generation. Furthermore, unlike existing models that use knowledge triples (entities) separately and independently, our model treats each knowledge graph as a whole, which encodes more structured, connected {$\longleftarrow$ 3. show the originality and advantages of this work} semantic information in the graphs. Experiments show that the proposed model can generate more appropriate and informative responses than state of- the-art baselines.” {$\longleftarrow$ 4. summary the performance gain of the model shown by
experiments}
-
Introduction
-
Introducing the background:
“Semantic understanding, particularly when facilitated by commonsense knowledge or world facts, is essential to many natural language processing tasks”
“Recently, a variety of neural models has been proposed for conversation generation”
-
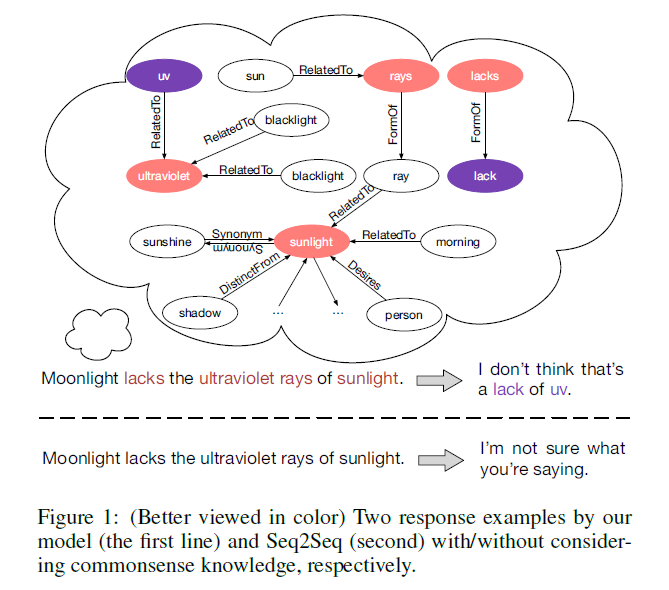
Explain motivation (an example is given):
“A model can understand conversations better and thus respond more properly if it can access and make full use of large-scale commonsense knowledge”
“For instance, to understand a post-response pair “Don’t order drinks at the restaurant , ask for free water” and “Not in Germany. Water cost more than beer. Bring you own water bottle”, we need commonsense knowledge such as (water, At Location, restaurant), (free, Related To, cost), etc.”
-
Drawbacks of previous work:
“First, they are highly dependent on …”
“Second, they usually …”
-
Introduction to our methods (and a graph is provided to help better understand the concept of introducing commonsense knowledge) :
“To address the two issues, we propose …”
“We use a large-scale commonsense knowledge …”, “To fully leverage the retrieved graphs …”
“In summary, this paper makes the following contributions: …”
-
- Paper
From Conjunctive Queries to Instance Queries in Ontology-Mediated Querying [paper]
- Abstract
“We consider ontology-mediated queries (OMQs) based on expressive description logics of the $\mathcal{ALC}$ family and (unions) of conjunctive queries, studying the rewritability into OMQs based on instance {$\longleftarrow$ 1. explain generally what this work has done} queries (IQs). Our results include exact characterizations of when such a rewriting is possible and tight complexity bounds for deciding rewritability. We also give a tight complexity bound for the related problemof deciding whether a given MMSNP sentence is equivalent to a CSP.” {$\longleftarrow$ 2. the results observed from this work}
-
Introduction
-
Explains a few (which means many terms aren’t specified) concepts and previous work:
“An ontology-mediated query (OMQ) is …” “An important step into this direction has been made by …”
-
Motivations of this work:
“There are two additional motivations to study the stated question. The first one comes from …” “The second motivation stems from …”
-
A detailed introduction about what this work has done:
“The main aim of this paper is to study the rewritability …” “Regarding IQ-rewritability as a decision problem, we show NP-completeness for the case of …” “We also consider …”
I really need to comment here:
Now I understand the suffering of reading something you truly unable to understand … (even if you searched online ** **and had a grasp about what it is, and that’s basically all you know about it). However, if given time, I still will be happy to dig deeper into this area and at least understand what this field is doing.
-
- Paper
Reasoning about Consensus when Opinions Diffuse through Majority Dynamics [paper]
- Abstract
“Opinion diffusion is studied on social graphs where agents hold binary opinions and where social pressure leads them to conform to the opinion manifested by the majority of their neighbors. Within {$\longleftarrow$ 1. Explain main concepts} this setting, questions related to whether a minority/ majority can spread the opinion it supports to all the other agents are considered. It is shown that, no matter of the underlying graph, there is always a group formed by a half of the agents that can annihilate the opposite opinion. Instead, the influence power of minorities depends on certain features of the given graph, which are NP-hard to be identified. Deciding whether the two opinions can coexist in some stable configuration is NP-hard, too.” {$\longleftarrow$ 2. introduce the background}
-
Introduction
-
Explain the background by a detailed example:
“Consider the following prototypical scenario. …”
-
Introduce the motivation of this work and previous work:
“Our goal is to analyze these questions under the lens of algorithm design and computational complexity.” “Indeed, while the study of opinion diffusion, originated in [Granovetter, 1978], has …”
-
Give a detailed overview of the following sections:
“In this paper we fill this gap. In more details, we first …” “Moreover, we evidence in Section 4 that …” “Finally, we address the question …”
-
- Paper
R-SVM+: Robust Learning with Privileged Information [paper]
- Abstract
“In practice, the circumstance that training and test data are clean is not always satisfied. The performance of existing methods in the learning using privileged information (LUPI) paradigm may be seriously challenged, due to the lack of clear strategies {$\longleftarrow$ 1. Introducing the background} to address potential noises in the data. This paper proposes a novel Robust SVM+ (RSVM+) algorithm based on a rigorous theoretical analysis. Under the SVM+ framework in the LUPI paradigm, we study the lower bound of perturbations of both example feature data and privileged feature data, which will mislead the model to make wrong decisions. By maximizing the lower bound, tolerance of the learned model over perturbations will be increased. Accordingly, a novel regularization function is introduced to upgrade a variant form of SVM+. The objective function of RSVM+ is transformed into a quadratic programming problem, which can be efficiently {$\longleftarrow$ 2. the detailed process of the proposed methods} optimized using off-the-shelf solvers. Experiments on real world datasets demonstrate the necessity of studying robust SVM+ and the effectiveness of the proposed algorithm.” {$\longleftarrow$ 3. the gains proved by the experiments}
-
Introduction
-
Introducing the background and concepts:
“This auxiliary information can be widely found in human teaching and learning process. For example …” “Inspired by this fact, Vapnik and Vashist [Vapnik and Vashist, 2009] introduced the paradigm of learning using privileged information (LUPI) …” “Since this auxiliary information will not be available at the test stage, it is referred to as privileged information.” “As one of the most popular classifiers, support vector machine (SVM) was first upgraded …”
-
Drawbacks of the current work:
“These methods have largely advanced the developments on LUPI. However, their successes are usually achieved …”
-
Contribution of this work:
“In this paper, we derive a novel Robust SVM+ (R-SVM+) …” “In this way, the capability of the learned model to tolerate …” “Experimental results demonstrate …”
-
- Paper
SentiGAN: Generating Sentimental Texts via Mixture Adversarial Networks [paper]
- Abstract
“Generating texts of different sentiment labels is getting more and more attention in the area of natural language generation. Recently, Generative Adversarial Net (GAN) has shown promising results in text generation. However, the texts generated by GAN usually suffer from the problems of poor quality, lack of diversity and mode collapse. In this {$\longleftarrow$ 1. introduce background and drawbacks} paper, we propose a novel framework - SentiGAN, which has multiple generators and one multi-class discriminator, to address the above problems. In our framework, multiple generators are trained simultaneously, aiming at generating texts of different sentiment labels without supervision. We propose a penalty based objective in the generators to force each of them to generate diversified examples of a specific sentiment label. Moreover, the use of multiple generators and one multi-class discriminator can make each generator focus on generating its own examples of a specific sentiment label {$\longleftarrow$ 2. a detailed introduction of the method and corresponding reasons} accurately. Experimental results on four datasets demonstrate that our model consistently outperforms several state-of-the-art text generation methods in the sentiment accuracy and quality of generated texts.” {$\longleftarrow$ 3. performance gain shown by the experiments}
-
Introduction
-
Introducing backgrounds:
“Unsupervised text generation is an important …” “Generative Adversarial Nets (GANs) …”
-
challenges may encounter:
“However, there are a few challenges to be addressed …”
-
detailed work-flow of the methods and a summary:
“We propose a new text generation framework …” “We use a well-performed sentiment classifier as evaluator to …” “The major contributions …”
-
- Paper
What Game Are We Playing? End-to-end Learning in Normal and Extensive Form Games [paper]
- Abstract
“Although recent work in AI has made great progress in solving large, zero-sum, extensive-form games, the underlying assumption in most past work is that the parameters of the game itself are known to the agents. This paper deals with the relatively under-explored but equally important “inverse” setting, where the parameters of the underlying game are not known to all agents, but must {$\longleftarrow$ 1. introduce background and drawbacks of recent work} be learned through observations. We propose a differentiable, end-to-end learning framework for addressing this task. In particular, we consider a regularized version of the game, equivalent to a particular form of quantal response equilibrium, and develop
1) a primal-dual Newton method for finding such equilibrium points in both normal and extensive form games; and 2) a backpropagation method that lets us analytically compute gradients of all relevant game parameters through the solution itself. This ultimately lets us learn the game by training in an end-to-end fashion, effectively by integrating a “differentiable game solver” into the loop of larger {$\longleftarrow$ 2. a detailed explanation of proposed methods} deep network architectures. We demonstrate the effectiveness of the learning method in several settings including poker and security game tasks.” {$\longleftarrow$ 3. demonstrate gains and effectiveness of the methods}
-
Introduction
-
Introduce the background of the task/motivation:
“Recent work in …” “However, virtually all this progress in game …” “In contrast, in many real world scenarios, …” “For example, in security games, we may want to …”
-
A detailed work-flow of what we did in this paper:
“In this paper, we propose …” “The crux of our approach is …” “We demonstrate the effectiveness of our approach …”
-
2017
- Paper
Foundations of Declarative Data Analysis Using Limit Datalog Programs [paper]
- Abstract
“Motivated by applications in declarative data analysis, we study $Datalog_\mathbb{Z}$—an extension of positive Datalog with arithmetic functions over integers. This language is known to be undecidable, so we propose two fragments. In limit $Datalog_\mathbb{Z}$ predicates are axiomatised to keep minimal/maximal numeric values, allowing us to show that fact entailment is coNExpTime-complete in combined, and coNP-complete in data complexity. Moreover, an additional stability requirement causes the complexity to drop to ExpTime and PTime, respectively. Finally, we show that stable $Datalog_\mathbb{Z}$ can express many useful data analysis tasks, and so our results provide a sound foundation for the development of advanced information systems.” {$\longleftarrow$ 1. the motivation and main work as well as gains are shown in sequential order}
-
Introduction
-
Background introduction:
“Analysing complex datasets is currently a hot topic …” “It has recently been argued that data analysis should be declarative …” “An essential ingredient of declarative data analysis is …” “This extensive body of work, however, focuses primarily …”
-
General introduction to the work and a summary over the contributions:
“To develop a sound foundation for …, we study …” “In limit $Datalog_\mathbb{Z}$, all intensional predicates with …” “We provide a direct semantics for …” “Our contributions are as follows.”
-
2016
- Paper
Hierarchical Finite State Controllers for Generalized Planning (Corrected Version) [paper]
- Abstract
“Finite State Controllers (FSCs) are an effective way to represent sequential plans compactly. By imposing appropriate conditions on transitions, FSCs can also represent generalized plans that solve a range of planning problems from a given domain. {$\longleftarrow$ 1. Introducing main concepts} In this paper we introduce the concept of hierarchical FSCs for planning by allowing controllers to call other controllers. We show that hierarchical FSCs can represent generalized plans more compactly than individual FSCs. Moreover, our call mechanism makes it possible to generate hierarchical FSCs in a modular fashion, or even to apply recursion. We also introduce a compilation that enables a classical planner to generate hierarchical FSCs that solve challenging generalized planning problems. The compilation takes as input a set of planning problems from a given domain and outputs a single classical planning problem, whose solution corresponds to a hierarchical FSC.” {$\longleftarrow$ 2. a detailed illustration of what this work has done}
-
Introduction
-
Introducing backgrounds:
“Finite state controllers (FSCs) are …” “Even FSCs have limitations, however. Consider …”
(and a graphic example was given here to help understand the drawbacks) -
Introducing our work (and reasonable ideas/motivations behind it) and summarize the efforts
“In this paper we introduce a novel formalism for …” “To illustrate this idea, Figure 2 shows an example hierarchical FSC …”
(another graphic example was given here to help understand the idea) “Intuitively, by repeatedly …” “Compared to previous work on the automatic generation of FSCs for planning the contributions of this paper are:”
-
2015
- Paper
Bayesian Active Learning for Posterior Estimation [paper]
- Abstract
“This paper studies active posterior estimation in a Bayesian setting when the likelihood is expensive to evaluate. Existing techniques for posterior estimation are based on generating samples representative of the posterior. Such methods do not consider efficiency in terms of likelihood evaluations. In order to be query efficient we treat posterior estimation {$\longleftarrow$ 1. background introduction and drawbacks of existing methods / motivations} in an active regression framework. We propose
two myopic query strategies to choose where to evaluate the likelihood and implement them using {$\longleftarrow$ 2. main work of this paper} Gaussian processes. Via experiments on a series of synthetic and real examples we demonstrate that our approach is significantly more query efficient than existing techniques and other heuristics for posterior estimation.” {$\longleftarrow$ 3. gains shown by experiments}
-
Introduction
-
Background introduction:
“Computing the posterior distribution of parameters given observations is a central problem in statistics.” “In some cases, we only have access to …”
-
Goal/motivation of the paper:
“Our goal is an efficient way to estimate …” “Given observations, we wish to make inferences about …”
-
Contribution (and it’s actually bold-lined in the paper as a subtitle):
“Our contribution is to propose …” “We propose two myopic query strategies on …” “and we demonstrate the efficacy …”
-
- Paper
Recursive Decomposition for Nonconvex Optimization [paper]
- Abstract
“Continuous optimization is an important problem in many areas of AI, including vision, robotics, probabilistic inference, and machine learning. Unfortunately, most real-world optimization problems are nonconvex, causing standard convex techniques to find only local optima, even with extensions like random restarts and simulated annealing. We observe that, in many cases, the local modes of the objective function have combinatorial structure, and thus ideas from combinatorial optimization can {$\longleftarrow$ 1. the background (drawbacks thus motivations)} be brought to bear. Based on this, we propose a problem-decomposition approach to nonconvex optimization. Similarly to DPLL-style SAT solvers and recursive conditioning in probabilistic inference, our algorithm, RDIS, recursively sets variables so as to simplify and decompose the objective function into approximately independent subfunctions, until the remaining functions are simple enough to be optimized by standard techniques like gradient descent. The variables to set are chosen by graph partitioning, ensuring decomposition whenever {$\longleftarrow$ 2. A detailed introduction of the method} possible. We show analytically that RDIS can solve a broad class of nonconvex optimization problems exponentially faster than gradient descent with random restarts. Experimentally, RDIS outperforms standard techniques on problems like structure from motion and protein folding.” {$\longleftarrow$ 3. gains shown by the experiments}
-
Introduction
-
Background:
“AI systems that interact with the real world often have to solve …” “However, most continuous optimization problems in …”
-
Methods and challenges to do this work:
“In this paper we propose that …” “We thus propose a novel nonconvex optimization algorithm, which …” “The main challenges in applying …” “For example, consider …”
-
Contributions:
“We first define local structure and then present our algorithm, …” “In our analysis, we show …”
-
Summary:
After analyzing Abstract / Introduction of the best paper award winner from 2015 ~ 2020, considering the:
structure (how / in what order the story is told, e.g., background, motivation, etc.) relations (how the corresponding part in Abstract and Introduction interacts with each other, e.g., callbacks.) writing skills (when and where and in what form an example should be provided)
We epitomize the common patterns shown in these papers and form a writing guidance:
For Abstract:
functionality of the Abstract:
Give a brief view of your work, including:
\[\begin{cases} \text{$\textbf{Introduction of your task / motivation}$ (some concepts, drawbacks)}\\ \text{$\textbf{A general view of how your work is done}$ (your key methods and why you do it in that way)}\\ \text{$\textbf{What your experiments told you}$ (usually stand as a proof for the efficiency of your work)} \end{cases}\] note that it’s better you don’t insert any pictures here, the job is to explain your work in simplest words without introducing any new concepts, thus some terms can be used here, and the confusions will be solved in ‘Introduction’
-
Explain the background of your work (basic concepts, drawbacks which later implicitly serve as the motivation of your work)
e.g.: xxx is … (give a brief view of what you’re doing here), however, xxx is … (explain drawbacks of the existing methods)
note that the twist (‘however’) is very important
-
A general introduction of the work (you can go with the sequential style or logical style etc.)
For sequential style: (in this style you basically are following the architecture of your work)
e.g.: we … (what you did first), then … (what you did based on your first step)
For logical style: (in this style you basically are following the logic of how you solve problem)
e.g.: we … to … (the first advancement you’re making), for …. (another advancement you’re making)
e.g.: we … to … (the first advancement you’re making), however …, (new problems raised by the first advancement)
thus …. (another advancement you’re making to solve the problem)
And of course you always can write in a way you feel the story is told straight
note that the reason / goal (to …) of what you’re doing is very important
-
Show and summarize the experimental results
e.g.: we demonstrate that …(on what your experimented), experiment results show our … can … (superiority of your work)
For Introduction:
functionality of the Introduction:
A detailed ‘Abstract’, which explains in details of what you did, in some sense, the abstract is like the guidance of the Introduction, where general aspects are introduced in Abstract, and a more detailed explanation of your work is done in Introduction
-
Background introduction: (the history of the subfield of this work, drawbacks, and an illustration (graphic / textual) to better understand the task / problem)
e.g.: … has been an important … (general introduction of your field), … in … proposed …(origin of your field here), recently … (some advancement here)
-
Drawbacks of the previous work and thus our proposal (how it’s down more specifically) as well as its challenges:
e.g.: …, however …, to solve the problem …, we … (here you can (not necessity) follow the introductory style used in your Abstract)
note that explaining challenges and how the proposals solve them respectively is very important
-
How your experiments are carried and a summary over your main contribution:
e.g.: we show … that … .
Our main contributions are as follows: (it’s better to write this in a new line)
note that the summarization of your work should be short and overall
Enjoy Reading This Article?
Here are some more articles you might like to read next: